เปรียบเทียบผลการ Query ระหว่างมีการใช้ HAVING และการใช้คำสั่งคำนวณลงใน WHERE

คำสั่งทั้งสองให้ผลลัพท์เหมือนกัน แตกต่างกันที่ คำสั่งแรกมีการใช้ HAVING ส่วนอีกคำสั่งมีการใส่คำสั่งคำนวณลงใน WHERE ตรงๆ
SELECT * FROM (
SELECT
O.id,
O.id AS contract_id,
O.lot_no,
O.job_id,
O.contract_no,
O.create_date AS date,
FLOOR((UNIX_TIMESTAMP() - O.create_date) / 86400) AS diff,
3 AS type,
O.create_date_comment AS comment,
O.create_date_alarm AS alarm
FROM `cdms_db`.`app_contract` AS O
WHERE O.`department` IN (1)
HAVING `diff` >= 55 AND `diff` > O.`create_date_alarm`
) AS Z;ก่อนอื่น ขออธิบายเงื่อนไขคำสั่งของด้านบนก่อน มีการคำนวณช่วงเวลาที่แตกต่างกันเก็บไว้ที่ diff และหลังจากเลือกข้อมูลเสร็จแล้ว มีการใช้ HAVING กรองข้อมูล diff ตามเงื่อนไขที่กำหนดอีกครั้ง ซึ่งผลการ Query เป็นไปตามรูปด้านล่าง สังเกตุเวลาประมวลผล (ลูกศรสีแดง) ที่รูปนะครับ
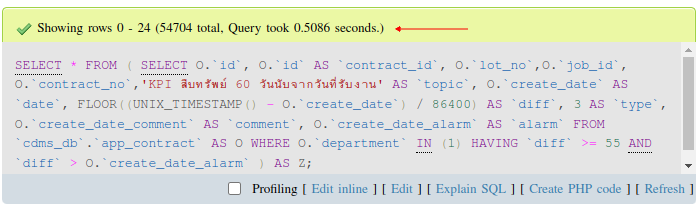
SELECT * FROM (
SELECT
O.id,
O.id AS contract_id,
O.lot_no,
O.job_id,
O.contract_no,
O.create_date AS date,
FLOOR((UNIX_TIMESTAMP() - O.create_date) / 86400) AS diff,
3 AS type,
O.create_date_comment AS comment,
O.create_date_alarm AS alarm
FROM cdms_db.app_contract AS O
WHERE
O.department IN (1)
AND FLOOR((UNIX_TIMESTAMP() - O.create_date) / 86400) >= 55
AND FLOOR((UNIX_TIMESTAMP() - O.create_date) / 86400) > O.create_date_alarm
) AS Z;พิจารณาที่เวลาประมวลผลในรูปด้านล่างเลยนะครับ ทั้งสองวิธีใช้เวลาในการประมวลผลแตกต่างกันมากโขอยู่ (ตรงลูกศรสีแดง)
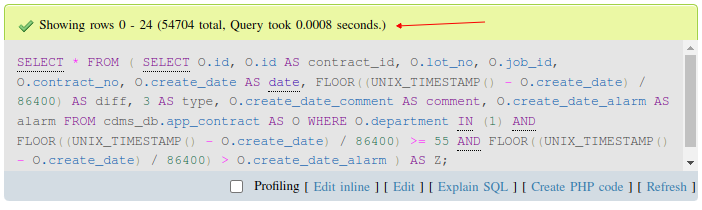
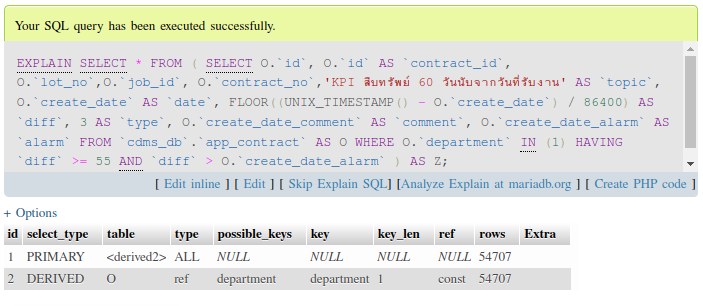
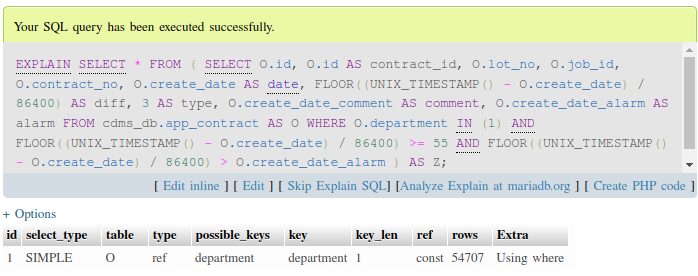
หมายเหตุ : เนื่องจากในคำสั่งนี้จำเป็นต้องใช้ SELECT ซ้อน SELECT (คำสั่งจริงๆมีมากกว่านี้) เลยตัดเอามาให้ดูเป็นตัวอย่างเฉพาะส่วนที่มีปัญหาเท่านั้น เผื่อต้องเจอเคสลักษณะนี้