ผมมี XML ของ docx ซึ่งอยากจะดึงมาค้นหาเฉพาะที่เป็น หัวข้อ1 2 3
<?xml version="1.0" encoding="UTF-8" standalone="yes" ?>
-
<?xml version="1.0" encoding="UTF-8" standalone="yes" ?>
- <w:document xmlns:ve="http://schemas.openxmlformats.org/markup-compatibility/2006" xmlns:o="urn:schemas-microsoft-com:office:office" xmlns:r="http://schemas.openxmlformats.org/officeDocument/2006/relationships" xmlns:m="http://schemas.openxmlformats.org/officeDocument/2006/math" xmlns:v="urn:schemas-microsoft-com:vml" xmlns:wp="http://schemas.openxmlformats.org/drawingml/2006/wordprocessingDrawing" xmlns:w10="urn:schemas-microsoft-com:office:word" xmlns:w="http://schemas.openxmlformats.org/wordprocessingml/2006/main" xmlns:wne="http://schemas.microsoft.com/office/word/2006/wordml">
- <w:body>
- <w:p w:rsidR="00297869" w:rsidRDefault="00F01E1C" w:rsidP="00F70BFA">
<w:bookmarkStart w:id="0" w:name="_GoBack" />
<w:bookmarkEnd w:id="0" />
</w:p>
- <w:p w:rsidR="00F01E1C" w:rsidRDefault="00F01E1C" w:rsidP="00F01E1C">
</w:p>
- <w:p w:rsidR="00F70BFA" w:rsidRDefault="00F70BFA" w:rsidP="00F70BFA">
</w:p>
- <w:p w:rsidR="00F70BFA" w:rsidRDefault="00F70BFA" w:rsidP="00F70BFA">
</w:p>
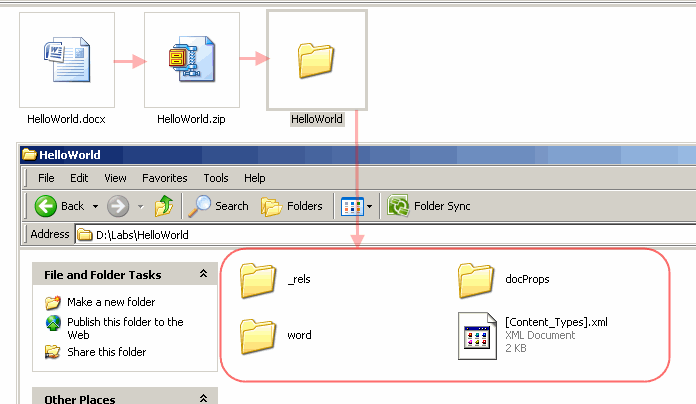
ไม่รู้จะดึงอย่างไงดีครับ พอทำเป็น zip แล้วแตกออกมาไฟล์มันกระจายย่อยมากๆ มีชื่อว่า document.xml คือเนื้อหาของเราแต่ไม่รู้ว่าจะเอาที่เป็น heading 1 และเนื้อหาใต้นั้นมาอย่างไงครับ
หรือเรียกง่ายๆว่าสกัดข้อความจาก Microsoft Word (Docx)
มีวิธีอื่นก็บอกได้ครับ
ส่วนวิธีการอ่านข้อความกับ docx โดยตรงยังไม่เคยเห็นครับ